From Diffusion-Based Visual Generation
to Verifiable Visual Coding
in Graphics Engines as World Simulators
Yan Zheng
Department of Computer Science
The University of Texas at Austin
Dissertation Defense · April 16, 2026
Committee: Zhangyang Wang (advisor), Qiang Liu, Georgios Pavlakos, Amy Zhang, Mingyuan Zhou
The World Model Landscape
How should AI understand and interact with the 3D physical world?
Current Approaches
- Video generation (Genie, Sora) — predict next frame
- 3D scene generation (Marble) — static, no interaction
- Latent prediction (V-JEPA) — no visual output
- Physical AI (Cosmos) — fixed action spaces
Shared Limitation
- Spatial intelligence = prediction
- No causal guarantees
- No verifiability
- No symbolic reasoning
Thesis Statement
Industrial graphics engines provide causal grounding and symbolic interfaces that complement neural generative models — enabling both verifiable spatial intelligence evaluation and geometry-grounded visual synthesis.
Three investigations:
- Flow Generation — understand flow model latent space, apply to 3D texture synthesis
- Neural 3D Geometry — can diffusion models generate production-quality meshes?
- Verifiable Spatial Intelligence — diagnose where VLM spatial reasoning breaks down
Thesis Overview
| Part I: Flow Generation |
OscillationInversion AAAI 2026 Oral Yan Zheng, et al., Zhangyang Wang FlowMorph WACV 2026 Yan Zheng, et al., Zhangyang Wang Flow-Optimizer / Straight-SDS CVPR'25 WS Yan Zheng, et al., Zhangyang Wang |
| Part II: Neural 3D Geometry |
Neural Volumetric Mesh Generator NeurIPS 2022 Workshop Yan Zheng, Lemeng Wu, Xingchao Liu, Zhen Chen, Qiang Liu, Qixing Huang |
| Part III: Verifiable SSI |
VoxelCodeBench ICML 2026 (review) Yan Zheng, Florian Bordes VeriWorld Bench (in progress) Yan Zheng, Zhangyang Wang |
Part I
Structured Visual Generation
via Flow Latent Space
Oscillation Inversion (AAAI 2026) · FlowMorph (WACV 2026) · Straight-SDS
Oscillation Inversion AAAI 2026 Oral
Fixed-point iteration for flow inversion: \(z^{(k+1)} = y - (\sigma_0 - \sigma_{t_0}) v_\theta(z^{(k)}, \sigma_{t_0})\)
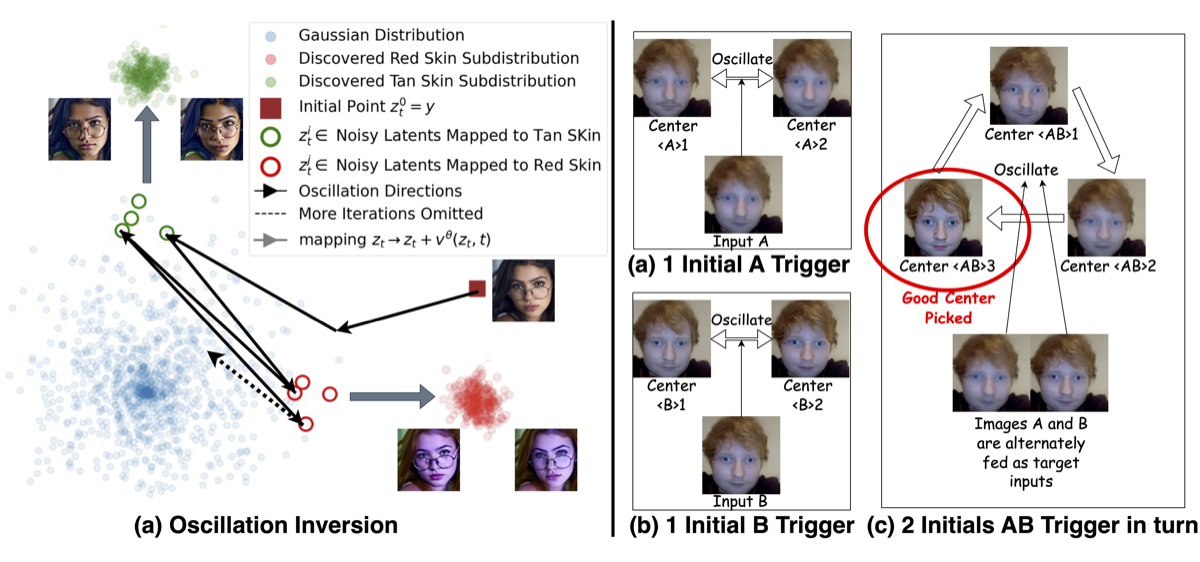
Discovery: In large flow models (FLUX, HunyuanVideo), this does not converge — it oscillates between semantically coherent clusters. Jacobian has singular values > 1 → locally expanding → oscillation guaranteed.
Why Does It Oscillate?
Problem Setup
Goal: find intermediate latent \(z_{t_0}\) such that one-step generation recovers image \(y\):
\(z_{t_0} + (\sigma_0 - \sigma_{t_0})\, v_\theta(z_{t_0}, \sigma_{t_0}) = y\)
Fixed-point iteration to solve:
\(z^{(k+1)} = y - (\sigma_0 - \sigma_{t_0})\, v_\theta(z^{(k)}, \sigma_{t_0})\)
Key Theoretical Result
- For Gaussian mixture targets, no stable fixed point exists
- Jacobian has singular values > 1 → locally expanding
- Iterates oscillate between semantically coherent clusters
- Not noise — each cluster shares consistent low-level features
Validation: Toy Data and Large Models
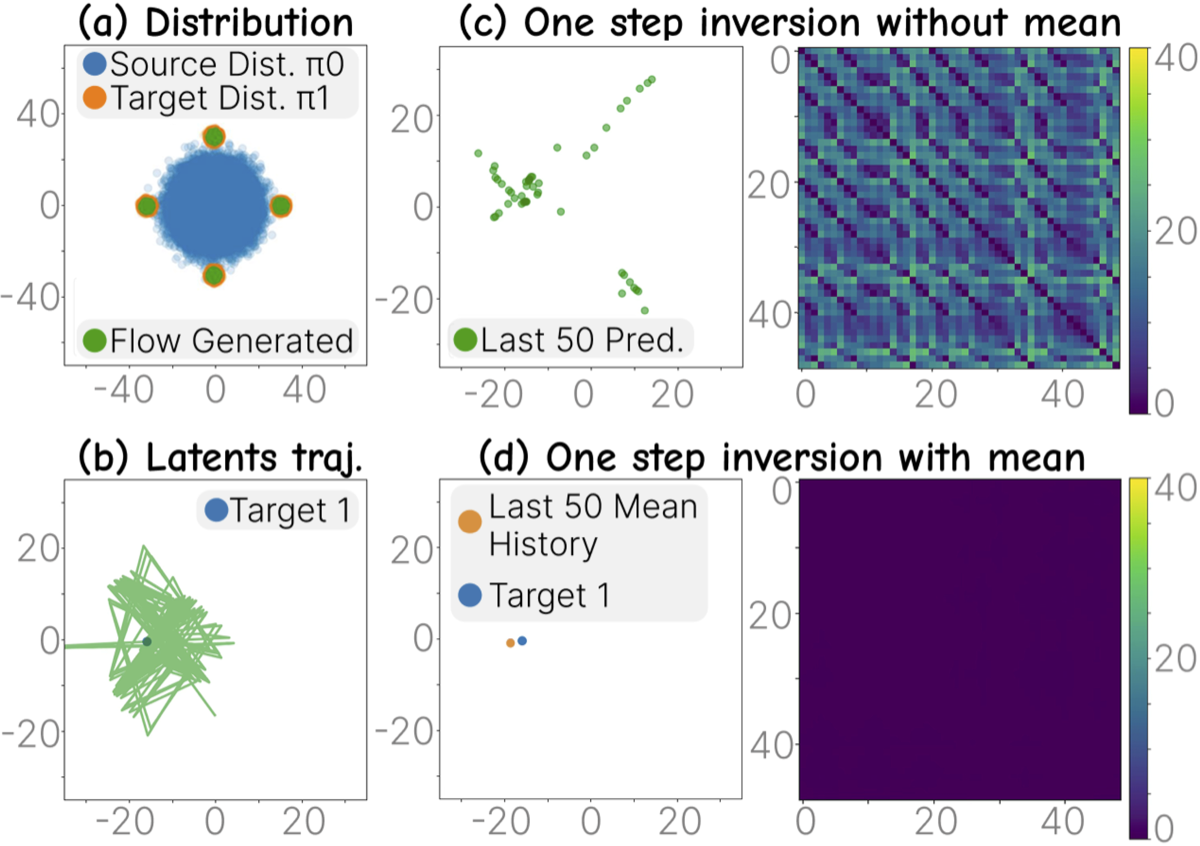
(a) Toy Gaussian mixture setting. (b–d) Averaging odd/even clusters recovers the true fixed point — validated by Theorem 1.
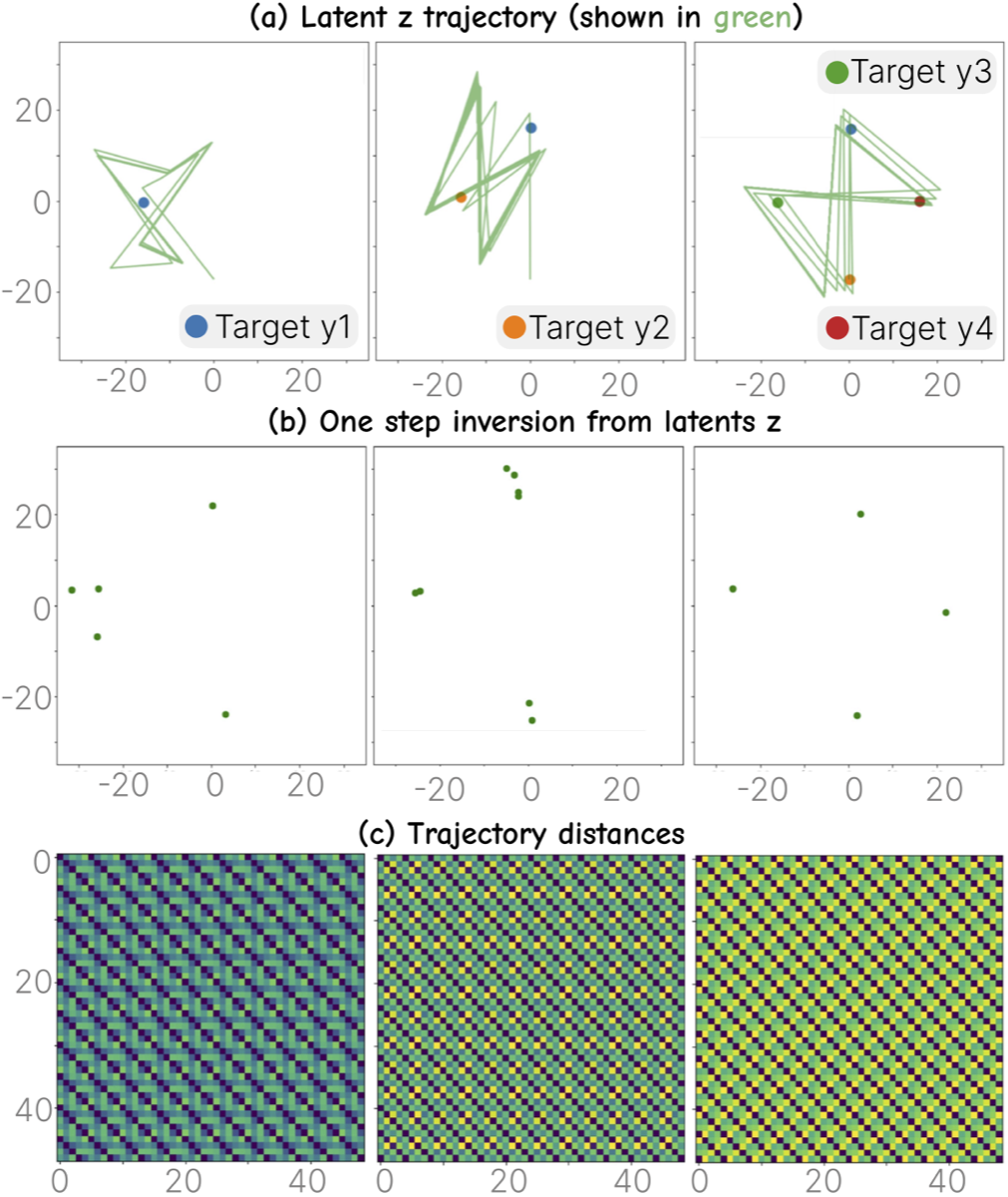
Trained flow matching on toy distribution. Columns: 1, 2, 4 input images. Row (a): inverted latents. Row (b): one-step predictions. Row (c): trajectory distances — more inputs → more regular oscillation.
Group Inversion: Controlling Oscillation
Instead of inverting one image, cycle through a group \(\{y_1, \dots, y_m\}\):
\(z^{(k+1)} = y_{(k \bmod m)} - (\sigma_0 - \sigma_{t_0})\, v_\theta(z^{(k)}, \sigma_{t_0})\)

Image Enhancement: Input A (low quality) twice + B → 3 clusters. Clusters 1,2 expelled (low quality). Cluster 3 pushed onto high-quality manifold.
- Key insight: oscillation expels undesirable components and retains the high-quality center
- No training, no fine-tuning — works on any flow model (FLUX, HunyuanVideo)
- Number of clusters matches the periodic number
Application 1: Image Enhancement
Group inversion fuses low-quality inputs → high-quality output.
Quantitative Results (CelebA)
| Method | Denoise PSNR↑ | Deblur LPIPS↓ | 4× SR LPIPS↓ | Time |
|---|---|---|---|---|
| BlindDPS | — | 0.257 | 0.345 | 270s |
| GDP | — | 0.304 | 0.357 | 118s |
| BIRD | — | 0.225 | 0.306 | 234s |
| Piscart | 28.21 | 0.15 | 0.12 | 7.8s |
| Ours | 25.50 | 0.12 | 0.17 | +9.5s |
Best LPIPS on denoise/deblur. Training-free, 8.74s/image on A6000.
Application 2: Training-Free Video Enhancement
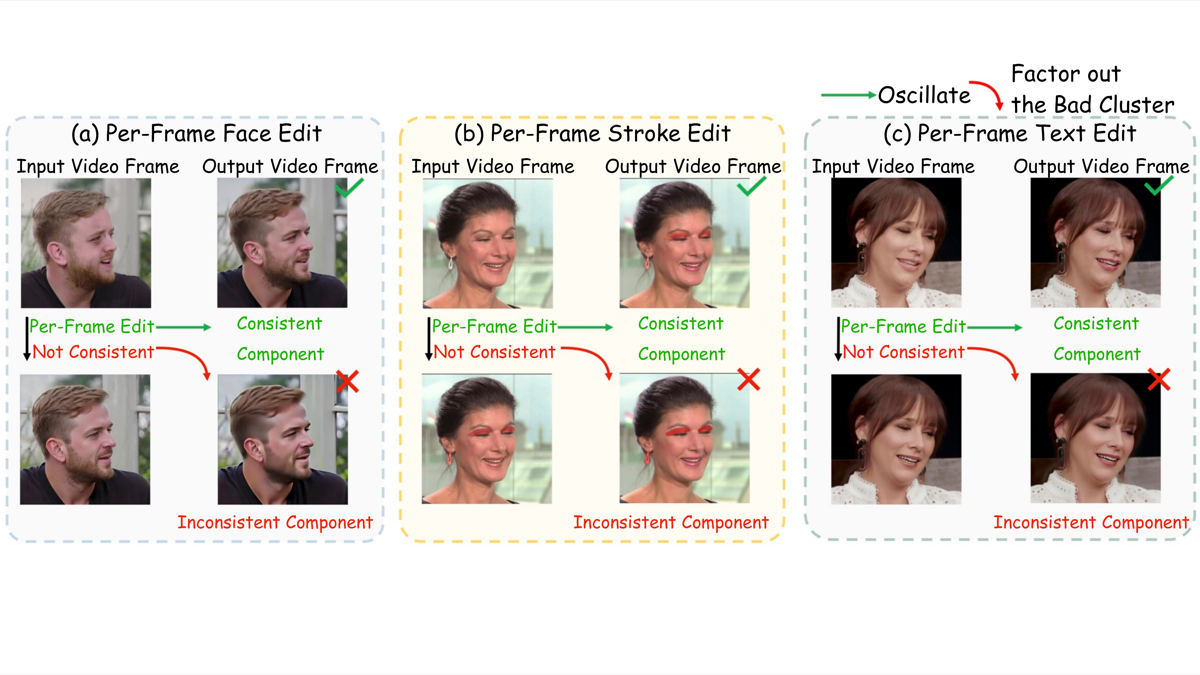
Per-frame Topaz → inconsistent. Group inversion (A+B) → consistent.
Temporal Consistency (VFHQ, blur σ=4)
| Method | flow_L1↓ | flicker↓ | T-LPIPS↓ | CLIP_TSC↑ |
|---|---|---|---|---|
| Topaz baseline | 5.090 | 0.132 | 0.0215 | 0.9910 |
| Ours | 5.150 | 0.138 | 0.0179 | 0.9922 |
Better T-LPIPS and CLIP consistency. Any per-frame editor → video editor, training-free.
FlowMorph: Problem WACV 2026
Why is image morphing hard?
- Naive interpolation → geometry drift
- Multi-step rollouts → unstable
- Existing methods trade geometry for semantics
Our insight
In rectified flow, geometry and semantics live in separable variables at a single noise level.

Smooth, identity-preserving transitions across poses and expressions.
FlowMorph: Two-Variable Decomposition
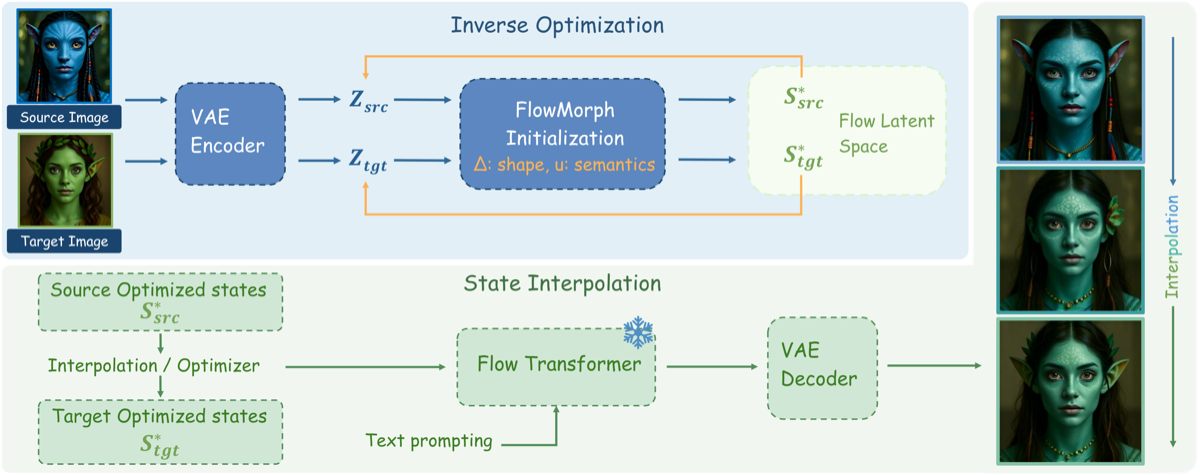
\(\mathbf{s}(\boldsymbol{\Delta}, \mathbf{u}) = (z_{t_i}^{(y)} + \boldsymbol{\Delta}) - \delta\sigma \cdot \mathbf{u}\)
\(\boldsymbol{\Delta}\) = geometry | \(\mathbf{u}\) = semantics | \(\delta\sigma\) = step length
Flow-Optimizer: optimize \((\Delta, u)\) → match target
Flow-Interpolation: linear \(\Delta\) + SLERP \(\mathbf{u}\) → smooth morph
Both training-free on any frozen flow model.
FlowMorph: Results

vs RF-Inversion, DiffMorpher, SDEditInterp, FreeMorph — ours preserves geometry with smoother transitions

Smooth morphing across identities, expressions, and styles
FlowMorph: Multi-Objective Composition
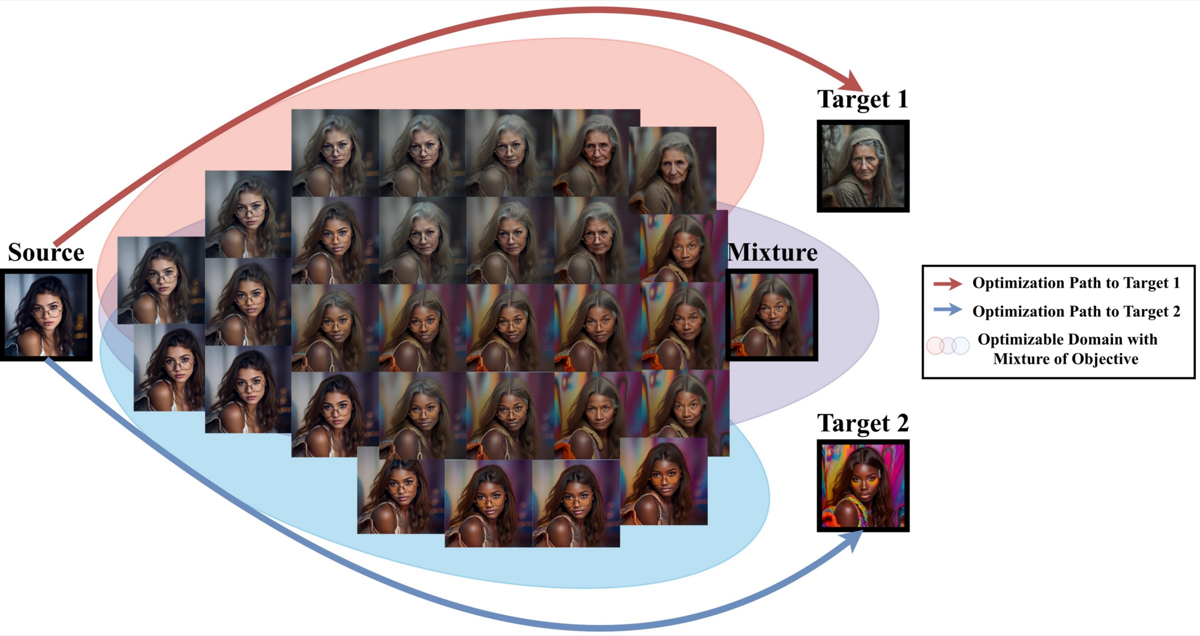
Composite loss: blend identity + expression + age + style simultaneously by combining multiple target losses. Each target contributes a gradient toward a different attribute — the optimization finds a balanced point.
Straight-SDS: From 2D Morphing to 3D Texturing CVPR'25 WS
The SDS Problem
- SDS starts from pure noise → blurry, over-saturated textures
- No structural alignment with mesh geometry
Our Fix: Oscillation-Initialized SDS
- Find stable latent region via oscillation inversion (not noise)
- Optimize texture from this region using Tweedie-based loss
Per-Iteration Pipeline
- Render current mesh from 4-cycle symmetric camera views
- Warp reference face → rendered pose (MediaPipe landmarks)
- FluxOptimizer: oscillation inversion on (rendered, warped) → edited image
- Loss = MSE(rendered, edited) + front_view + normal_reg
- Backprop → update kd (diffuse) + ks (specular) + normal textures
Combines Oscillation Inversion (AAAI) + FlowMorph (WACV) into a 3D pipeline.
Straight-SDS: Reference → 3D Texture
Single reference image → 4K UV texture on MetaHuman mesh. ~5 min on A6000.

Reference

Multi-view renders (Peking Opera makeup)


Harley Quinn style transfer
Straight-SDS: Full Gallery

Straight-SDS: UV Texture + Gallery

Optimized 4K diffuse (kd) texture map — directly usable in UE5


Geisha style: reference → multi-view 3D
Works only because UE5 MetaHuman provides the geometric scaffold — the flow model handles appearance, the engine handles structure.
Part I: Key Insight
Flow models produce stunning visual content — but cannot generate or maintain 3D geometry on their own. Straight-SDS works only because MetaHuman provides the geometric scaffold.
This raises the question: can neural models generate 3D geometry end-to-end? → Part II
Neural Volumetric Mesh Generator NeurIPS 2022 Workshop
Can diffusion models generate production-quality 3D meshes end-to-end?
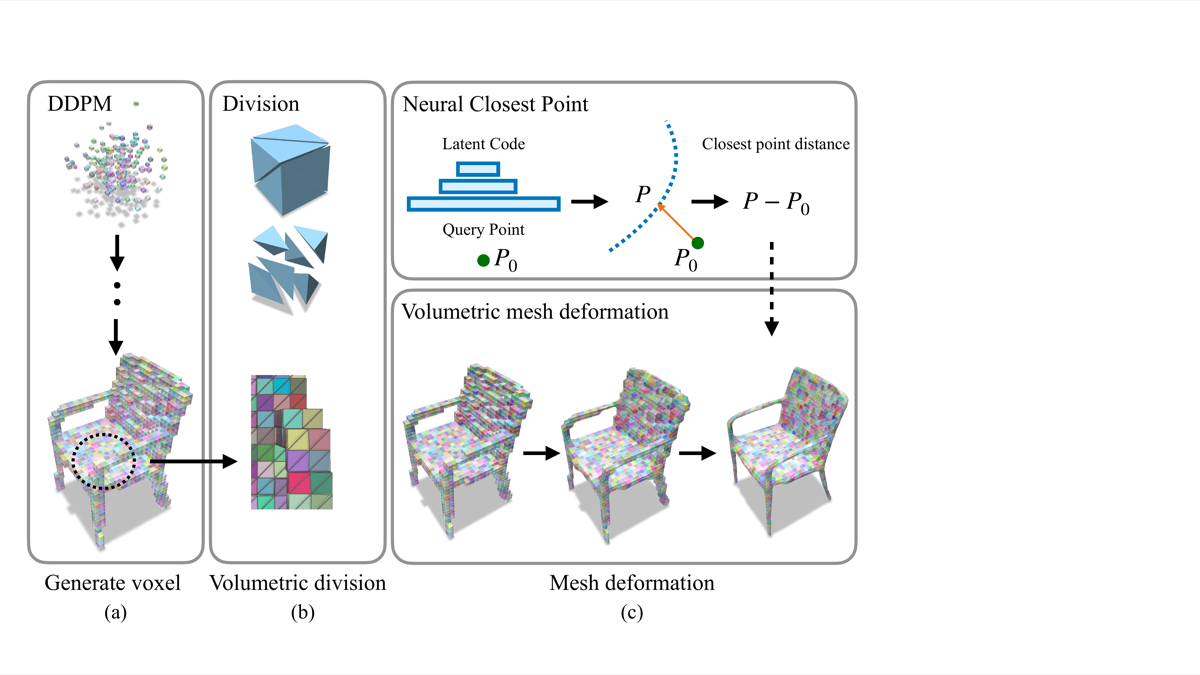
Voxel DDPM → volumetric division → neural surface deformation

Ablation: red = flipped faces. Even full model has artifacts.
Lesson: Neural mesh generation remains fragile — production-quality 3D geometry is better provided by engines than generated by networks. This motivates the engine-based approach.
From Generation to Evaluation
Parts I & II show:
- Flow models generate visual content but need geometric scaffolding
- Diffusion models cannot reliably generate production-quality 3D geometry
Conclusion: Graphics engines should provide the geometry. But can AI agents use them? Can they reason spatially through code? → Part III
Part III
Code-Based 3D Generation &
Verifiable Spatial Intelligence
VoxelCodeBench · VeriWorld Bench
Related: Code-Based 3D Generation
A growing body of work uses executable code as the representation for 3D content, replacing raw mesh/voxel outputs with programs that generate geometry.
| Work | Input | Output | Engine | Key Idea |
|---|---|---|---|---|
| MeshCoder NeurIPS'25 |
Point cloud | Blender Python scripts | Blender | Part-decomposed, quad-dominant mesh via code. 41 categories, 86.75% IoU. |
| Code2Worlds ICML'26 |
Text | Simulation code (4D) | Blender | Text → physics-aware 4D scenes. Dual-stream generation + VLM critic for dynamic fidelity. |
| VoxelCodeBench (Ours) ICML'26 (review) |
Text | Python scripts | Unreal Engine 5 | Benchmark: evaluate code generation for 3D. 220 tasks, 8 models, automated visual reward. |
Our position: MeshCoder and Code2Worlds generate code for 3D content in Blender. VoxelCodeBench evaluates code generation in UE5 with deterministic metrics — complementary to generation-focused work.
VoxelCodeBench arXiv: 2604.02580 · Open-sourced
Can LLMs build 3D worlds through code in Unreal Engine?
220 tasks across 3 complexity axes:
- Symbolic (80) — coordinate mapping, patterns, primitives
- Geometric (50) — boolean ops, iterative construction
- Artistic (90) — multi-object scenes, thematic coherence
Open-source platform: VoxelCode renders LLM-generated Python in UE5 with Voxel Plugin 2.0

Representative outputs: characters, shapes, animals, vehicles, architecture
VoxelCodeBench: Results across 8 Models
| Model | Shape % | Quality /10 |
|---|---|---|
| GPT-5 | 87.9 | 5.71 |
| GPT-5 Mini | 80.4 | 4.86 |
| Claude Sonnet 4.5 | 80.4 | 5.01 |
| GPT-5 Chat | 69.7 | 3.66 |
| Claude Opus 4 | 69.4 | 4.13 |
| Claude 3.5 Sonnet | 66.9 | 3.30 |
| Claude 3 Opus | 45.2 | 3.40 |
| Gemini Pro | 19.5 | 1.36 |
Per-Category Breakdown
| Symbolic | Geometric | Artistic | |
|---|---|---|---|
| GPT-5 | 87.5 | 66.7 | 97.5 |
| Claude S. 4.5 | 90.3 | 52.8 | 89.5 |
Geometric construction is the bottleneck: 21pp drop from symbolic → geometric
VoxelCodeBench: Code Generates Internal Structure

Code-based generation produces objects with coherent internal geometry (ladders, cabin interiors, floor layouts) — impossible with surface-only neural 3D methods
Open-sourced: github.com/facebookresearch/voxelcodebench
Platform + benchmark + evaluation tools
Work done at Meta (FAIR)
UELivePy: Plugin Architecture
11 custom UE5 plugins, 75K+ lines of C++, 45K+ lines of Python runtime, built over 2 years.
| Plugin | Lines | What it does |
|---|---|---|
| UELivePy | 45,677 | Embeds CPython 3.11 inside the game runtime. WebSocket hot-injection, per-frame Tick callbacks, dynamic reflection of all BlueprintCallable functions. |
| SlangCudaPlugin | 30,472 | Integrates Slang shader compiler + CUDA compute into UE5. Agents write GPU shaders at runtime — compiled, executed, and hot-reloaded without restart. |
| MotionHelper | 18,061 | Exposes animation, IK solving, and motion matching to Python. Enables AI-driven character behavior. |
| MovieHelper | 15,480 | Runtime MovieRenderQueue + LevelSequence control. Agents can record videos, set up cinematic cameras programmatically. |
| RuntimeCore | 8,997 | Low-level C++ runtime bridge: tick scheduling, memory management, inter-plugin communication. |
| NiagaraHelper | 5,975 | Particle system control — spawn, configure, animate Niagara effects from Python. |
| VoxelHelper | 5,963 | Terrain manipulation: heightmaps, material weights, stamps — integrates VoxelPlugin 2.0. |
| ChaosHelper | 2,990 | Physics destruction: fracture meshes, apply forces, trigger Chaos physics events. |
| ClothHelper | 2,420 | Cloth simulation control: wind, constraints, material properties at runtime. |
Engineering & Research Impact
Engineering
- No existing solution: UE5's built-in Python stops when the game starts. No runtime Python exists in the industry.
- Engine modifications: Custom C++ changes to UE5 source — reflection system hooks, GameThread scheduling, CUDA interop
- Cross-language bridge: Python ↔ C++ ↔ Blueprint ↔ CUDA/Slang — 4 language boundaries with type conversion
- Concurrency: Python GIL + UE5 GameThread + GPU async — all must be synchronized
Research Impact
- Low-cost world simulator: packaged builds for both Windows and Linux, each instance uses only ~4GB VRAM — dozens of parallel runs on a single GPU node
- VoxelCodeBench (Ch. 4): 100+ GPU distributed evaluation pipeline for 3D code generation
- VeriWorld (Ch. 5): 128+ controlled ablation runs across 3 models, 6 maze configs, 4 action spaces
- World generation: natural language → composed skill scripts → interactive 3D worlds in real time
Open-sourced for the research community. The infrastructure enables reproducible, large-scale spatial reasoning evaluation at low cost.
Infrastructure: Runtime Code Execution in UE5
Existing engine Python scripting runs only in the editor. We embed a full runtime inside the game process.
Editor-Only Python
- Stops when game starts
- No frame loop (one-shot only)
- No remote access
- No LLM integration possible
Our Runtime (UELivePy)
- Runs in editor, game, server, packaged builds
- Per-frame Tick callbacks — continuous control
- WebSocket hot-injection — LLM sends code remotely
- Dynamic reflection — auto-exposes all APIs
This is how LLM agents control the engine: write code → inject via WebSocket → execute inside running game → observe result → iterate.
Runtime Hot-Injection + Frame-Level Tick
1. Remote Code Injection
ws.send(json.dumps({
"jsonrpc": "2.0",
"method": "python_exec",
"params": {"code": """
import unreal_runtime as ur
actor = ur.Engine.GameplayStatics
.GetPlayerCharacter(None, 0)
"""}
}))2. Per-Frame Tick Callback
def spotlight_follow(dt, elapsed, actors, p):
char, light = actors
pos = char.GetActorLocation()
pos.Z += 500
light.SetActorLocation(pos)
return elapsed < p["duration"]Why this matters
- Hot-injection: No restart, no recompile
- Tick = continuous control: 60fps Python callbacks
- Iterative: Observe → modify → re-inject
- Composable: Multiple tasks run concurrently
AI character behavior · World generation from prompt
Result: Complex World Generation
"Build a dark misty forest at dusk" → agent composes 8+ skill folders
Trees, rocks
Sun, fog
Particles
Wind anim
Terrain
Materials
Cinematic
Sub-levels
30+ API calls composed. No predefined tool set could anticipate this combination.
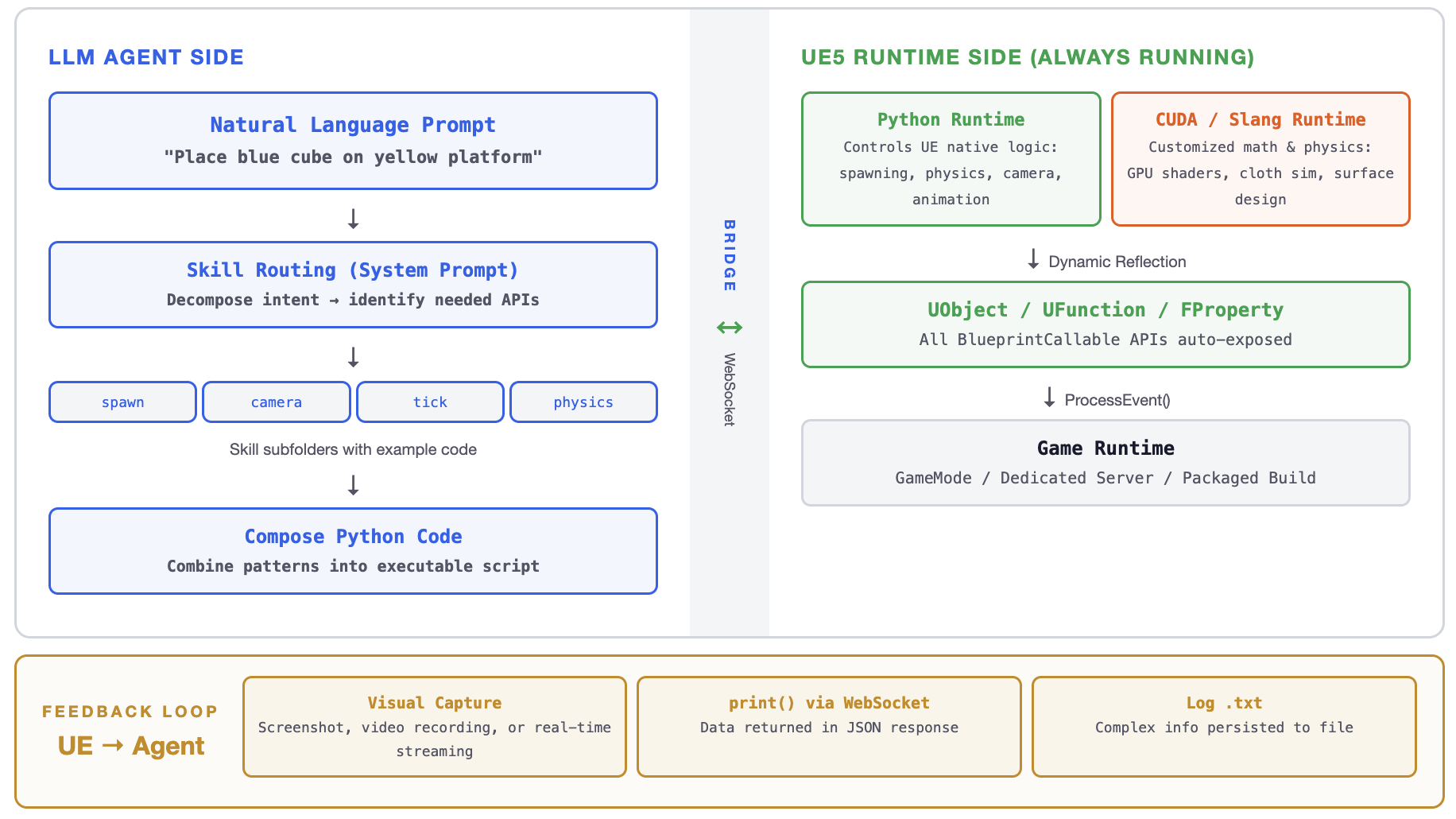
Agent–Engine bridge: LLM → WebSocket → Python + CUDA/Slang → UE5
Dynamic API Self-Discovery
import unreal_runtime as ur
import inspect
# Discover all engine modules
dir(ur.Engine)
# → ['Actor', 'GameplayStatics',
# 'KismetMathLibrary', ...]
# Discover methods on a class
dir(ur.Engine.GameplayStatics)
# → ['SpawnActor', 'GetPlayerController', ...]
# Read function signature
inspect.signature(
ur.Engine.GameplayStatics.SpawnActor
)
# → (ActorClass, SpawnTransform, ...)- Zero-shot generalization: LLM faces unseen UE project → explores via reflection → writes working code
- No manual registration: New plugin installed? API instantly available
- Self-correcting: Inspect return types, read errors, adjust — full REPL loop
- Scales with the engine: New features auto-exposed
MCP equivalent: manually write JSON schema for 10,000+ engine functions. Every update requires maintenance. Doesn't scale.
UELivePy is a Platform, Not Just Infrastructure
What we built (Chapters 3–4)
An open platform where anyone can:
- Write a natural language task description
- The platform generates an interactive 3D environment in UE5
- An agent (VLM + harness) interacts with the environment in real time
- A verifier checks the outcome deterministically
No UE expertise needed. Write a task spec → get a benchmark instance.
What we do with it (Chapter 5)
VeriWorld uses this platform to systematically evaluate VLM spatial reasoning:
- Generate diverse task families (navigation, physics, coding)
- Run controlled ablations (V / S / C / Csel)
- Vary action space (batch / single / aim-and-fly)
- Diagnose where and why models fail
Platform → Benchmark → Diagnosis.
The infrastructure enables the science.
VeriWorld: Benchmark + Diagnostic Tool
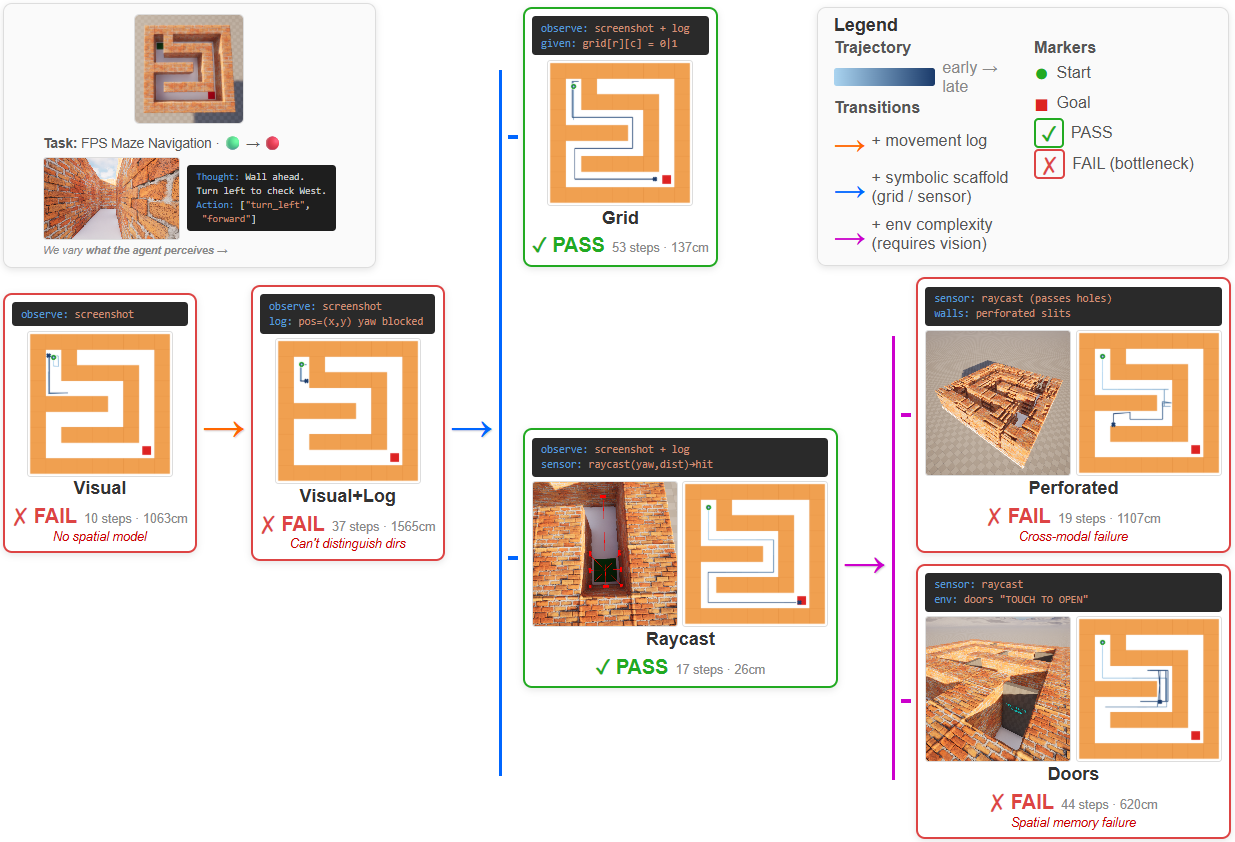
Same maze task under controlled input conditions. Structured (raycast) passes; visual-only fails. This controlled comparison isolates perception as the bottleneck.
VeriWorld: Pipeline
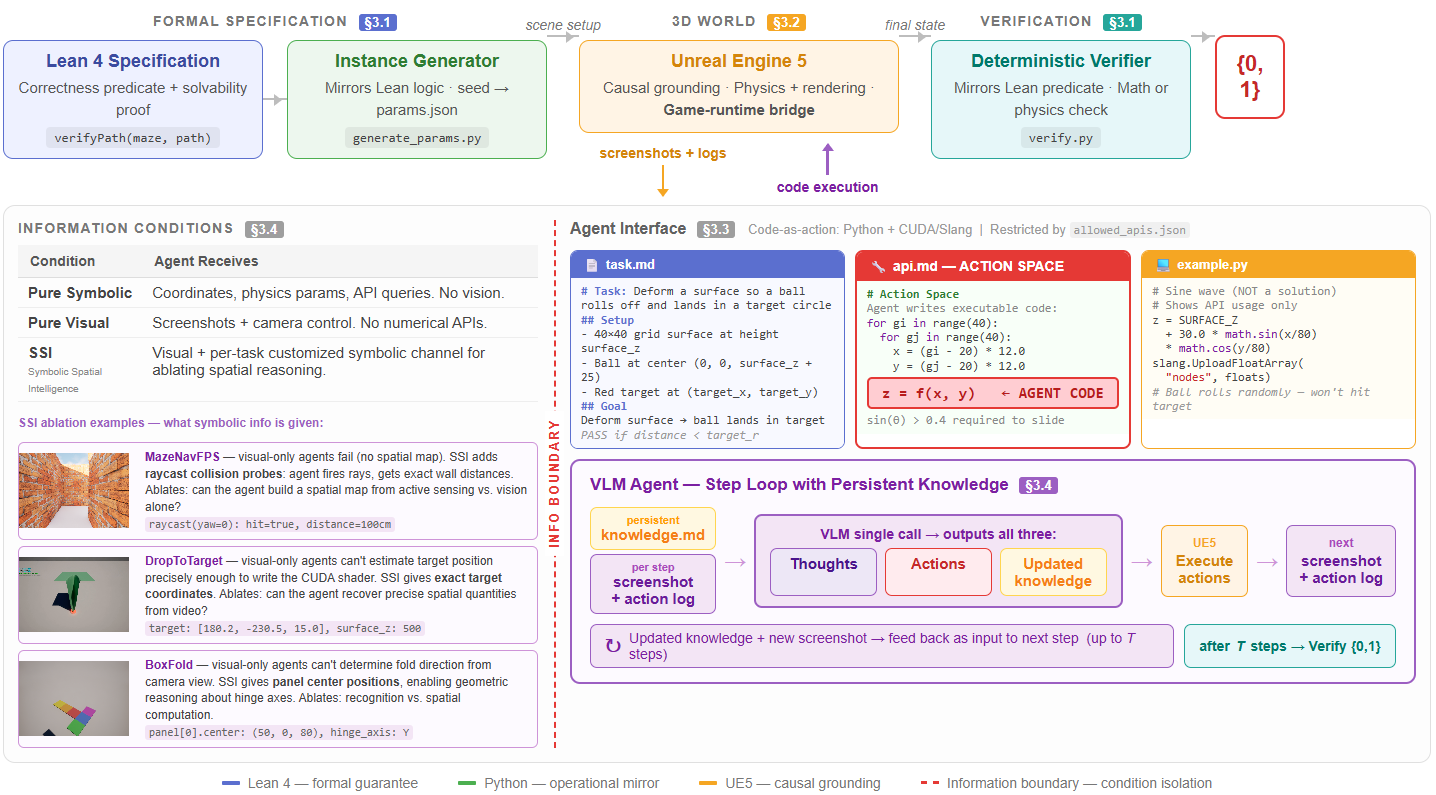
Lean 4 spec (proves solvability) → parametric instance generation → interactive UE5 environment → agent closed loop → deterministic pass/fail verifier.
VeriWorld: Task Family Demos
Interactive 3D tasks with deterministic verification. Agent observes, acts, receives feedback in a closed loop.
BoxFold — fold cube net into closed cube
BallSlide — deform surface so ball reaches target
Four-Condition Diagnostic Design
Same task, same verifier, same environment — vary only the information exposed:
| Condition | Agent Receives | What It Tests |
|---|---|---|
| V (Visual) | Screenshots / video only | Can the model extract spatial structure from pixels? |
| S (Structured) | Coordinates, geometry, physics params | Can the model reason given ground truth? |
| C (Combined) | V + S (all information) | Does more information help? |
| Csel (Selective) | V + selected structured info | Which specific information bridges the gap? |
The S−V gap measures perception difficulty. C vs Csel reveals that selective exposure matters more than amount.
Benchmark Results: Visual-to-Structure Gap
Across task families (BoxFold, MazeNavFPS, DropToTarget), models achieve 0.75–0.91 pass rate under S but only 0.05–0.15 under V.
- S−V gap is +0.67 to +0.79 — systematic, not instance-specific
- Naive combined (C) does not always help — sometimes hurts
- Selective (Csel) consistently recovers close to S performance
- One task shows V > S reversal — visual feedback loop is more natural
Takeaway: The bottleneck is not reasoning — models can solve tasks when given structure. The bottleneck is extracting that structure from visual input.
What to expose matters more than how much to expose.
BoxFold: Perception Bottleneck
Visual: FAIL

Overhead camera — cannot determine fold direction

Side camera — oscillates between +90° and -90°
Symbolic: PASS

Given position data → computes fold signs algebraically → completes cube
Same model, same task. S pass + V fail → perception is the bottleneck.
Task Difficulty: Two Axes

Horizontal: visual extraction difficulty. Vertical: symbolic reasoning difficulty. No single modality dominates — the selection of what to expose matters more than the amount.
Batch vs Single: What Happens Inside the Maze
Single-step: Scanning Loop (FAIL)




Step 2: turn left → new screenshot → "should I go this way?"
Step 3: turn right → new screenshot → "or this way?"
Step 4: turn left → new screenshot → stuck in place
Model re-evaluates from scratch after every action. Never commits.
Batch: Commit and Go (PASS in 5 steps)



Step 2: [fwd, turn_left, fwd, fwd] → execute all → one screenshot
Step 5: reached goal ✓
Model must commit to a plan. Forces forward progress.
Aim-and-Fly: How Tunnel Navigation Works




Each turn: "I see the hole upper-right"
→ set yaw=+15, pitch=+5, forward=150
→ fly toward hole → new screenshot
→ adjust → fly again
Reactive control based on visual feedback
Plan: [fwd 300, turn 45, move_z 50, fwd 200]
→ execute all blindly
→ curved tunnel changed direction mid-sequence
→ hits wall, stuck
Can't pre-plan for continuous curves
One move at a time (turn + forward)
→ no integrated aim-then-fly structure
→ can turn OR move, not both at once
→ oscillates at tunnel entrance
Lacks the right action primitive
Case Study 1: Grid Maze — Batch Wins


| VP Batch | VP Single | VRP Batch | VRP Single | N | |
|---|---|---|---|---|---|
| Gemini | 92%/9.3 | 10%/24.0 | 100%/15.9 | 90%/16.2 | 42 |
| Opus | 77%/17.6 | 0%/34.0 | 80%/17.9 | 20%/24.8 | 43 |
| GPT-4.1 | 31%/27.4 | 0%/34.0 | 30%/25.2 | 10%/32.5 | 43 |
Case Study 2: 3D Tunnel — Active Control Wins



| VP Active | VP Batch | VP Single | VRP Active | VRP Batch | VRP Single | N | |
|---|---|---|---|---|---|---|---|
| Gemini | 75%/20 | 40%/22 | 0%/30 | 75%/23 | 33%/12 | 0%/30 | 40 |
| Opus | 12%/14 | 25%/26 | 38%/25 | 12%/15 | 33%/26 | 25%/27 | 43 |
| GPT-4.1 | 25%/29 | 0%/30 | 0%/30 | 62%/23 | 0%/30 | 38%/27 | 42 |
WavyShooter — Visual PASS via Iterative Aiming
R0: MISS (wrong timing)
R3: closer (adjusted pitch)
R6: HIT ✓
DropToTarget — Symbolic PASS in 2 Rounds
R1: FAIL — slope too steep, overshot
R2: PASS ✓ — reduced angle, lands in circle
CurvyBilliards — Both V and S FAIL
Observe: bumpy Gaussian terrain
R1: wrong angle
R3: triangulated target, terrain deflects
VeriWorld: Key Findings
- Visual-to-structure gap is systematic — models succeed with structured input but fail to extract the same information from pixels (S−V gap +0.67 to +0.79)
- Selective exposure > raw combination — Csel consistently outperforms naive C. What to expose matters more than how much.
- Action space is a confounding variable — batch vs single can flip pass/fail. The optimal protocol is task-dependent (batch for mazes, aim-and-fly for tunnels).
- Material and scene settings affect visual difficulty — 3-tile checkerboard > uniform brick (Appendix ablation across 3 materials)
Spatial reasoning in VLMs is not a single capability — it is a combination of perception, structure extraction, reasoning, and harness-dependent execution. VeriWorld makes each component independently testable.
Summary
| Flow Generation | Oscillation dynamics, geometry-semantics decomposition, MetaHuman texture synthesis | AAAI WACV |
| Neural 3D Geometry | Volumetric mesh generation — reveals limits of neural 3D | |
| Verifiable SSI | VoxelCodeBench + VeriWorld: diagnostic benchmark for spatial intelligence | ICML |
Graphics engines provide the causal scaffolding that neural generation needs, and the verifiable environment that spatial intelligence evaluation requires.
Thank You
Questions?
Yan Zheng · yan.zheng@utexas.edu